Setting up AI Infrastructure with sensitive data (part 1)
I have been looking on the internet to find some information on hosting AI training software with little luck. Here is my setup, maybe it will help you make better decisions.
The training rig
With a strict budget limit of $15k, we are not going to outperform Alibaba servers, but we will setup a decent training rig with secure object storage.
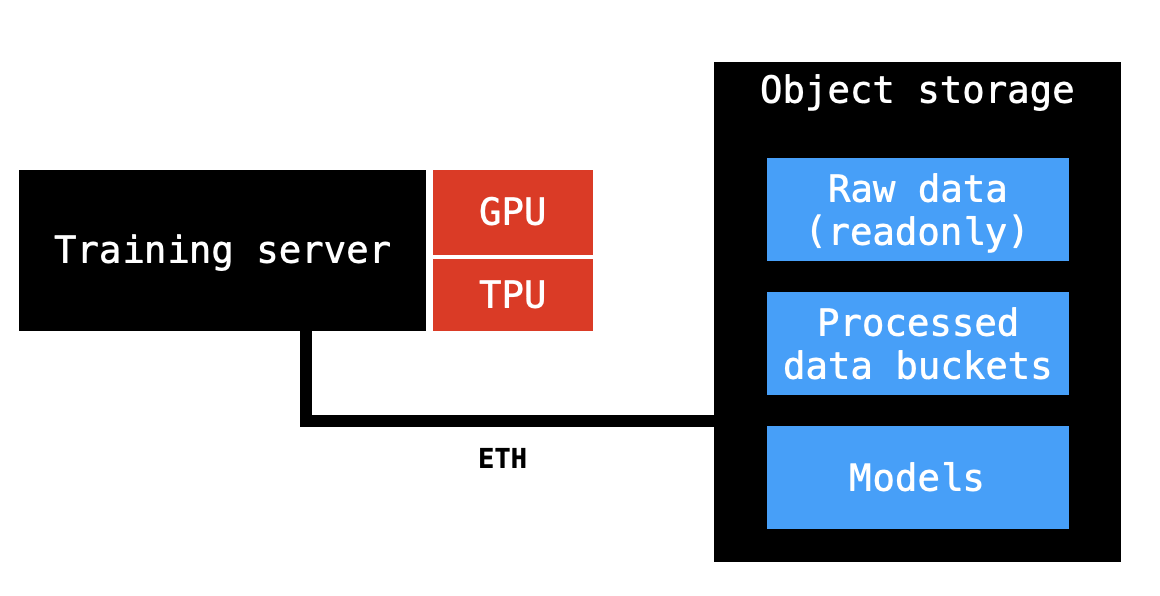
Labeled data will keep flowing from collection sites. It will be put in a readonly bucket. Experiments will need differently processed data, so a processed data will be stored at different buckets. The Object Storage server should be able to handle all that securely and efficiently.
Objectives
- data privacy
- on-premise computing
- reproducible models
- models optimized for specialised hardware (quantization aware training)
- team collaboration
This training setup is suppose to suit our specific use-case, which includes PII data. If that wasn’t the case I would go with one of the cloud services.
Servers specs
Training server
- CPU Intel® Xeon® GOLD 5220R, 24 cores, 2.2 GHz, 35.75MB L3 cache (150W) - RAM 32GB RAM, DDR4 ECC Registered 2666 MHz - GPU GeForce RTX 3090 24GB - 1.6TB Samsung SSD PM1725b, HHHL PCIe 3.0 x8, NVMe
Storage server
- CPU Intel® Xeon® E-2224, 4 rdzenie, 3.4 GHz, 8MB L3 cache (71W) - RAM 16GB DDR4 ECC Unbuffered 2666 MHz - SSD SATA 240GB, 2.5in SATA 6Gb/s, enterprise - Disk HDD SATA, 8TB, 7200rpm, Enterprise
Software
A few open source object storage solutions are available, I chose min.io. For extra security it is configured in SSE-S3 mode, where the secret key is managed by outside KMS.
For running experiments we use Jupiter Lab. We have created a shared space on disk to be able to share notebook without the trouble of going through git repos. A Coral TPU M.2 is connected to the AI server to run quantized neural networks the same way as they are on the Edge.
For data versioning we stick with DVC, which makes some redundancies but is really helping to organise training.
Experiments are being tracked using Weights & Biases. It is a pretty expensive service, but we found it the easiest to use. We also use W&B Sweeps to automate the hyperparameter tunning, it is very convinient.
W&B is an outside service, so we don’t post any data there. At some point plan is to use on-prem experiment tracking.
In Part two I will share how data flows during the experiment.
Let me know on twitter if you enjoyed this read.